O13: How Do AI Evals Work?
What AI evals are, why they matter, and how to run one on your LLM integration
You built the feature. You integrated the LLM. Now someone’s asking: How do you know it’s working? How do you test it? How do you make it better?
Those three questions have a four-step answer. It’s called an AI eval.
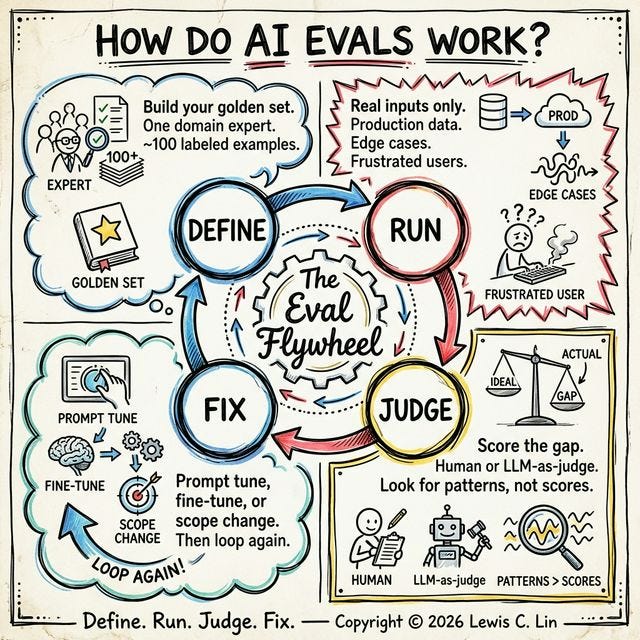
The Four Steps
DEFINE → RUN → JUDGE → FIX → (repeat)Step 1 — Define the Golden Set
Define what good looks like. Build your golden set.
Before your AI touches anything, your domain expert — the person with the most credible judgment in your product area — writes down what the right answer is. Not roughly right. Specifically right.
Their labeled examples become your golden set.
How to build it:
Identify your domain expert — your best support agent, most experienced paralegal, or senior engineer
Have them label ~100 real examples: good outputs and bad ones
Their judgment is the standard — no consensus, no committee
⚠️ Skip this step and you’re measuring nothing.
What one golden set entry looks like:
Input: “How do I cancel my subscription?”
Gold standard answer: “Go to Settings → Billing → Cancel. You’ll keep access until the end of your billing period.”
Why it’s good: Direct, correct, no jargon, tells the user what happens next
Failure mode if wrong: Hallucination or incomplete answer
Step 2 — Run the Model
Feed your AI real questions. Not easy ones.
Take the inputs your actual users send and run them through your model. Collect every output.
What “real” means:
